
你不知道的具身智能:从小机器狗到 Optimus
太长也要读
今年 4 月我组装了一台小机器狗,做的过程在推特上发过几条,大伙应该都刷到过,从买零件、装结构,到最后它能听懂指令、走两步、还能对话几句。
缘由要从过年那段时间说起,那阵子我天天用 Opus 4.6 写代码,发现很多地方它写得比我好,又快又准,越用越 FOMO,于是就想,要不试试软硬件结合的东西,这块相比纯软件可能还有一点门槛。
真想做了,方向很快就落到具体问题上,传感器怎么读,舵机怎么控,通信怎么兜底,电池、结构件和故障怎么处理。这些都比「做一台机器人」实在,于是我买了 STM32、ASRPRO、ESP32-C3、MG90S 舵机、OLED、DHT11、锂电池,还有一套 3D 打印结构件,凑成一台能听懂话、会趴下、会走路、还能接云端 AI 对话的小机器狗。
真上手才发现,最费时间的反而是各种小细节,MG90S 舵机 4 个里总有一个不太稳,OLED 我带电插一次就直接烧了,又多等了几天零件。直到 DeepSeek 对话、温湿度读取和动作控制都真跑起来,我才慢慢体会到「AI 进入物理世界」是什么意思。
从软件视角看,具身智能很容易被理解成给大模型接上一副身体,但真把线插上、电机转起来、结构件震起来,感受完全不一样,一条自然语言指令一路要变成结构化意图、动作序列、PWM、力矩、电流和接触,每一层都有自己的时间、能量和误差预算,还冒出一堆纯软件里根本不用操心的问题。
发完「你不知道的大模型」那篇文章后,有小伙伴起哄,看来你要写「你不知道的具身智能」了。我一想这台小机器狗刚好能帮上忙,虽然很皮毛,但我想聊的「感知、空间、动作、力矩」这些具身智能的基本概念,它身上其实都有,于是就开始了。
文章前半写这台机器狗的创造过程,后半是我基于公开论文、官方博客、开源项目和第三方资料整理的学习笔记,希望能给在 AI 之外、也想了解具身智能的朋友,多一个工程师视角。
先把小机器狗跑起来
这台小机器狗最后做成了一个低成本异构系统,加起来成本大概 200 多的样子,能听到唤醒词后进入对话,把用户指令交给云端 LLM 做语义理解,再把返回的结构化动作转成 STM32 能执行的舵机控制。
| 模块 | 型号/规格 | 价格区间 | 负责的事 |
|------|----------|----------|----------|
| 主控 | STM32F103C8T6 | ¥5-10 | 舵机控制、传感器读取、基础动作逻辑 |
| 离线语音 | ASRPRO | ¥15-25 | 唤醒词和本地关键词识别 |
| 联网模块 | ESP32-C3-MINI | ¥10-15 | Wi-Fi、配网、云端 AI 对话 |
| 辅助 Wi-Fi | ESP-01S | ¥8-12 | 备用通信通道 |
| 舵机 | MG90S 金属齿 × 4 | ¥40-60 | 四条腿的角度控制 |
| 传感器 | DHT11 | ¥5-10 | 温湿度读取 |
| 显示 | 0.96 英寸 OLED | ¥10-15 | 状态显示 |
| 电源 | 3.7V 1000mAh 锂电 | ¥15-20 | 供电 |
| 结构件 | 3D 打印 PLA | ¥20-30 | 机身和四条腿 |把它拆成数据流,对调试很有帮助。后面很多卡住的地方,最后都落在周边硬件上,比如唤醒词误触发、联网超时、舵机角度或供电不稳,这些偏硬件的坑甚至能整理成一张排查表:
| 步骤 | 输入 | 输出 | 常见问题 |
|------|------|------|------------------|
| 唤醒 | 环境音频 | 唤醒事件 | 误唤醒、漏唤醒、噪声 |
| 联网 | 唤醒事件和用户语音 | 云端请求 | Wi-Fi 配网、断线、超时 |
| 意图解析 | 文本或音频 | 结构化动作 | 参数范围、动作名称、上下文 |
| 本地通信 | 结构化动作 | UART 帧 | 校验、丢包、重传 |
| 运动执行 | UART 帧 | PWM 输出 | 抖动、供电、舵机偏差 |
| 状态回传 | 传感器和执行结果 | 文本或语音回复 | 读数延迟、失败状态表达 |一开始也想过,要不要换一颗更强的芯片全包了,真接线以后发现不是一回事,唤醒、联网、PWM、传感器读取、云端请求,各自要处理的延迟和稳定性都不一样。

ESP32-C3 负责 Wi-Fi 和云端 AI,接入 2.4GHz 网络,把语音或文本转给云端模型,再把结果发给 STM32。它比 STM32 更适合联网,但如果同时承担 PWM、多路串口、网络请求和对话状态,调度会很快变重。
ASRPRO 负责离线唤醒,低功耗监听环境声,识别到唤醒词再拉起联网,比全程上传音频更省电,也少一些隐私压力。
STM32F103 是 72MHz 的 ARM Cortex-M3,Flash 64KB、SRAM 20KB,跑模型不现实,做硬实时控制刚好;4 个 MG90S 舵机用 50Hz PWM 控角度,0.5-2.5ms 脉宽对应 0-180 度,硬件定时器能稳定输出微秒级 PWM,舵机走路时就不容易被任务调度带偏。
大概清明节前的那个周五零件和工具就全部到了,当天晚上开始整,持续几天,最后它从一堆零件变成了一台绑着线、能走好几步、能听懂简单指令的小机器狗,挺有趣的。

这里也用到 MCP 的概念,只不过在这台小机器狗里更简单,就是给模型和设备定一份「能力清单」。设备把自己能干的事报上去,模型照着清单调用。
对我最有用的地方,是把哪些能力留在本地、哪些能力交给云端先分清楚:设备端控制扬声器、LED、舵机、GPIO 等本地硬件,云端扩展智能家居、PC 操作、知识搜索、邮件等能力,这样边界会清楚很多。
实际完整走一遍是这样的,ESP32-C3 先上报自己有哪些能力(servo_control、sensor_read、gpio_write),我说「曼波坐下」,云端模型生成一个结构化调用(目标舵机、目标角度、速度参数),ESP32-C3 把它翻成 UART 指令发给 STM32,STM32 再一步步调整 PWM、回传执行状态。

这套小系统已经能听懂「坐下」、「站起来」、「现在温度多少」。空间能力完全没有,自己在哪里、椅子在哪里、往左走两步会不会撞到,全不知道。
机器人怎么知道自己在哪
小机器狗听不懂「往左走两步绕过椅子」,它根本不知道椅子离自己多远,也不知道自己在房间里站哪儿、朝哪边,更没有一张能持续更新的 3D 地图,深度感知、位姿估计、空间地图,这三样能力它都没有。
补空间能力不是再多接一个模块。深度相机、IMU、能跑 SLAM 的板子一上来,成本、功耗、算法栈就完全不一样,STM32 那套小系统也接不住。
后面还会多出四条新链路:「相机标定」要处理内参、畸变、曝光和同步;「位姿估计」要算清相机、IMU 和机身坐标之间的变换;「地图更新」要考虑环境变了之后旧地图怎么失效或修正;「动作规划」则是地图上可达,不等于真实脚底能稳定落下。
小机器狗如果只在桌面上演示,可以绕开这些问题。一旦放到房间里,地板反光、桌腿遮挡、线缆、台阶和光照变化都会进来。
图像模型擅长回答「这张图里有什么」这种 2D 问题,但机器人还得继续回答:这个物体离我多远,遮挡是什么情况,从哪个方向抓更稳,移动一步以后视角和支撑点会怎么变。
在 2D 图像里,一个杯子只是几百个像素。放到机器人世界里,一个杯子是有体积、重量、摩擦、遮挡和接触面的物体。机器人常用的 3D 表示主要有下面这几种,工程代价差别不小:
| 表示 | 解决的问题 | 工程代价 |
|------|------------|----------|
| Occupancy / Voxel | 哪些空间被占据,哪里能走 | 需要多视角或深度估计,分辨率和算力要权衡 |
| Point Cloud | 传感器原生 3D 几何 | 点云稀疏、无序,语义处理成本高 |
| NeRF / 3D Gaussian Splatting | 重建高保真场景,生成新视角 | 训练、更新和动态物体处理仍然麻烦 |
| 3D Scene Graph | 房间、物体和关系的空间记忆 | 依赖稳定感知和语义绑定 |这张图是我用 ChatGPT Image2 画的,把几类 3D 表示放在一起看,差别会更直观一点。

低层避障常用 occupancy 或局部 cost map,抓取看点云和末端位姿,长期任务需要 scene graph 这种带关系的空间记忆。难的是把它们放到同一个时间轴和坐标系里,3D 场景一旦无法持续更新,很快就会变成过期照片。小机器狗完全没有后两者,所以「往左走两步绕过椅子」这种指令根本没法执行。
SLAM 和点云擅长几何,能给位姿和障碍物,但语义弱,系统知道前面有一团点,却不知道那是椅子还是纸箱。NeRF 和 3D Gaussian Splatting 擅长重建和生成新视角,对机器人来说,更要看它们能不能把仿真、数据增强和世界模型拉近真实场景。
3D Scene Graph 更接近长期记忆,它把房间、桌子、杯子、抽屉这些对象变成节点,把「杯子在桌子上」「抽屉属于柜子」「钥匙上次在玄关」变成关系。家庭机器人要回答「我上次把扳手放在哪里」,只存一堆视频帧很难做到。
空间记忆还必须保留不确定性。机器人只在画面里看过一次杯子,就不该永久相信它还在原处。对象名称、最近观测时间、置信度和可见性,实现时都要一起存。

VLA 也在从 2D 往 3D 迁移。早期 RT-2、OpenVLA 主要把 2D 图像、语言和动作连起来,桌面抓取够用,但指令如果变成「把被挡住的蓝色积木拿出来」,2D 像素就不够了。机器人要知道蓝色积木被谁挡住,是否要先移开挡住它的物体,移开后是否会让别的东西掉下来。
3D-VLA、SpatialVLA 这类工作尝试把 3D 场景、SE(3) 位姿(位置加朝向,6 个自由度)和动作生成合到一起。Figure 的 Helix 系列虽然可以从单目视觉输入工作,但它仍然需要在内部学到深度、可操作性和物体关系。显式输入可以是 2D,内部表征要进入 3D。

单目摄像头做人形机器人同样需要权衡。单目可以通过多视角、运动视差和神经网络估深度,但需要足够的数据和稳定运动。主动深度或 LiDAR 是用硬件换确定性。Tesla、Figure、Boston Dynamics、宇树的传感器选择不同,背后是在视觉数据、算力、实时性和安全冗余之间取舍。
这也是我这台小机器狗的边界,它能把语言变成动作,但动作还不在空间里,没有位姿、地图和遮挡处理,「往左走两步」这种指令还是没法落地。
从写死的动作到 VLA
我那台小机器狗跑的还是固定动作,你说「坐下」,它就调出一组预设好的舵机角度,并没有真的从画面和语言里生成新动作,只是在语音入口前面加了一层意图识别。
在真实的具身智能里,VLA(Vision-Language-Action)才是值得细看的方向,把视觉、语言和机器人状态一起喂给同一个模型,让它直接输出动作,减少「视觉检测、语言理解、规划、控制」之间一堆手写接口,不过接口少了,排错难度反而会增加不少。
| 路线 | 代表工作 | 动作怎么表示 | 放到真机上会怎样 |
|------|----------|--------------|----------|
| 离散 token | RT-1、RT-2、OpenVLA | 把连续动作离散成 token | 容易接入语言模型,但精度和序列长度受限 |
| 动作块 | ACT | 一次预测未来 k 步动作 | 减少高频控制的累计误差 |
| 扩散生成 | Diffusion Policy、RDT-1B | 从噪声逐步生成动作轨迹 | 适合多模态动作,比如左绕或右绕都合理 |
| 流匹配 | π0、π0.5、SmolVLA | 生成连续动作分布 | 采样更快,更适合低延迟控制 |
| 高低频双系统 | Helix、Gemini Robotics 系列 | 高层推理拆任务,低层 VLA 执行动作 | 更接近大脑和小脑分工 |同样是「输出动作」,有的模型给关节角,有的给末端执行器(手或夹爪)的位移,有的给夹爪开合。关节角贴近硬件但难跨机器人迁移,末端位姿更通用却要配上逆运动学。

最早是 RT-1,把 13 万条演示、700 多个任务喂给 Transformer,第一次把机器人控制当成序列学习。RT-2 再把互联网图文混进来训,让模型把网上学到的常识也带进控制,代价是连续的关节、位姿、夹爪压成 token 会丢精度,动作一多 token 串也跟着变长。
ACT 更直接,把动作打包成一小段一起预测。ALOHA 用一对便宜的遥操作臂就能插 USB、拉拉链、煎蛋,到现在还是很多人上手模仿学习的第一站。Diffusion Policy 解决的是「绕开障碍物」这种有多条合理路径的情况,普通回归容易学出个直接撞上去的折中动作,扩散从噪声一步步生成,反而能把几种都对的走法都保住。
π0 改用流匹配,采样快不少。π0.5 再把泛化往开放环境推,混进高层子任务、口头指令和网页数据一起训。Physical Intelligence 给的结果是训练环境越多、到新家越稳定,大约 100 个环境就追平了「直接在目标环境训练」。
SmolVLA 走另一头,把门槛压到消费级硬件,450M 参数、只用社区数据、3 万条 episode 以内就能跑,能力未必最强,但把 VLA 从大公司集群里解放了出来。社区数据多样性要覆盖光照、相机角度、房间和演示质量,和软件工程里的测试集类似,单一实验室的干净数据,未必比一批有噪声但覆盖更广的更管用。
2025 年后高低层分工更明确。Google DeepMind 的 Gemini Robotics 就是一路,ER 1.5 负责理解和拆任务,配套的 VLA 管把每步变成动作,还出了 On-Device 版,本地低延迟,50-100 条演示就能适配新任务。
这种分工演示起来往往很好看,但放到产品里就容易暴露问题。「按本地垃圾分类规则整理桌面」,高层模型要查规则、拆步骤、解释意图,低层模型要识别每个物体并放进正确容器,两层混成一个黑盒,真出了问题就很难排查。
Figure 的 Helix 也走分层系统。早期 Helix 里 S2 是低频 VLM,S1 是 200Hz 动作策略;Helix 02 又补了 1kHz 的 S0 全身控制层,把平衡、接触和协调放到更快的一层。小机器狗里的处理方式也类似,慢模型做理解可以,平衡、接触和协调得交给更快的一层。
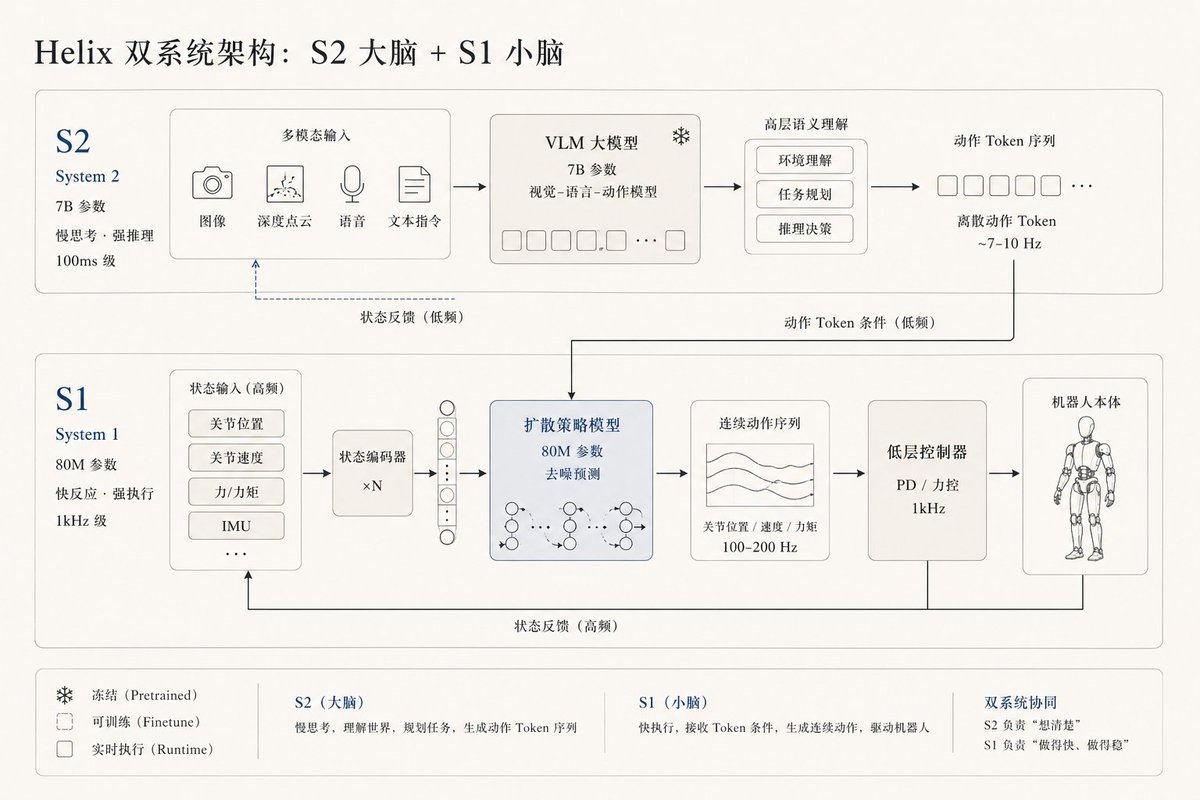
机器人大脑的难点,除了听懂话,还得考虑动作怎么表示。动作太粗抓不准,动作太慢控制不稳,一旦动作不连续,真实电机和接触又会把误差放大一截,最后效果就会偏得很明显。
绕不开的时间、能耗、数据
如果要把机器人系统的控制层拆一下,我一般分成大脑、小脑、肢体三块,落到工程里,其实就是不同频率的控制问题。
| 层级 | 负责什么 | 典型时间尺度 | 常见技术 |
|------|----------|--------------|----------|
| 大脑 | 视觉理解、语言交互、任务拆解 | 100ms 到 1s | VLM、VLA、LLM、GPU/NPU |
| 小脑 | 轨迹生成、平衡、动作协调 | 1ms 到 50ms | MPC、RL、IK、实时 CPU |
| 肢体 | 电机电流、编码器反馈、急停 | 微秒到 10ms | MCU、FPGA、EtherCAT、CAN-FD |小机器狗里也有这个分层,不过是极简版本。DeepSeek 对话是大脑,STM32 里的步态序列是小脑,PWM 和舵机是肢体。它不做动态平衡,1-2 秒的云端响应也能接受,但换成人形机器人,1 秒的平衡延迟就足够让它摔倒。
大脑层慢一点没关系。机器人听到「把杯子放进水槽」,会把它拆成找杯子、走过去、抓起来、松手,这种语义活儿不需要 1kHz。但小脑不行,它得快。人站着走着其实就是个倒立摆,控制回路一般得跑 200Hz 到 1000Hz,低了一受扰动就出问题。
再往下到肢体层就更要硬实时。电机控制要看编码器、估速度、限电流,一旦不对就立刻停掉,很多系统干脆把这一块放到专用 MCU 或 FPGA 上,避开 Linux 这类调度带来的不确定延迟。
延迟出在哪一层,表现完全不同。大脑慢,你觉得反应迟钝;小脑慢,一碰就倒;肢体慢,电机先抖再发热。
还有个容易被低估的坑,大脑、小脑各用各的坐标系,传感器又快慢不一(IMU 几百赫兹、摄像头几十赫兹、编码器上千赫兹),得靠标定和时间戳把它们对到同一个时间、同一套坐标上。标定一旦漂了,模型拿到的状态就跟真实世界对不上号,算法看着像是突然变笨,所以很多机器人 Debug 会先回到传感器、外参、零点和时间戳。

聊完时间,第二块就是能耗,机器人同样绕不开执行器和电池。一个人形机器人有几十个电机,电机、减速器、丝杠、编码器和驱动器往往是 BOM(整机的零件成本清单)里最贵、最难规模化的部分。
灵巧手尤其难。电机、腱绳、触觉、线束和散热全得塞进巴掌大的地方,所以很多公司反复打磨手部。人一天约 2000 kcal、折合 2.3kWh 就能活动很久,机器人没有骨骼韧带那套被动支撑,站着不动也得一直靠耗电撑着姿势。
第三块是训练数据,比普通大模型的数据难采太多了。文字能爬,图片能标,自动驾驶靠满街的车就能收一堆,可轮到机器人操作,你得有真硬件、有场地、有人看着,还得划好安全边界,这些都备齐了再开始采,成本直接高一个数量级。数据大致从这几个地方来:
| 数据来源 | 优点 | 短板 |
|----------|------|------|
| 人类遥操作 | 动作质量高,任务语义清楚 | 一个人通常一次教一台机器人 |
| 真机自主运行 | 最接近部署分布 | 失败有硬件和安全成本 |
| 仿真数据 | 可并行、可复现、便宜 | 摩擦、形变、接触和视觉质感有差距 |
| 人类视频 | 规模大,覆盖真实物体 | 缺少机器人动作标签和本体状态 |
| 合成数据 | 容易覆盖长尾场景 | 需要证明能提升真机策略 |仿真本来想绕开采集的麻烦,但它和真机终究不一样。光照、摩擦、间隙、磨损、传感器噪声、电机发热,仿真里都很干净,真机上却全是。比较稳的做法是先在仿真里把策略练到不犯低级错误,再拿少量真机数据校一遍,把失败样本收回去再训。指望仿真一步到位的,基本都会低估接触和传感器的误差,光靠仿真那点数据其实远远不够。
Tesla Optimus 这个工程样本
我很喜欢 Tesla,也很早就买了它的股票,所以看 Optimus 难免带一点个人偏好。单独写 Optimus,是因为它把 FSD 迁移、纯视觉、端到端训练、自研执行器、工厂试跑和大规模制造放在同一台机器上。拆开研究它,手从演示灵巧走到长期可靠要多久,失败样本怎么补上接触数据,制造体系怎样把执行器、线束、传感器和电池做成可维护产品,这些问题都会更具体。
表里的数字来自 Tesla AI Day、财报电话会和第三方技术整理,主要是一些公开口径和目标。记得当年 AI Day 的 PPT 和视频被不少机器人公司一帧一帧研究,这件事本身就很有意思。
| 项目 | 早期公开口径 | Gen 3 相关口径 | 为什么重要 |
|------|--------------|----------------|----------|
| 身体基础自由度 | AI Day 2022 披露 28 个基础 DoF,手另算 | 仍围绕 28+ 身体 DoF 展开 | 身体运动已经很复杂,主要变动集中在手和前臂 |
| 手部自由度 | 每只手 11 DoF,6 个执行器 | 下一代手和前臂公开提到 22 DoF,第三方整理提到每手 25 个执行器 | 灵巧操作空间变大,线缆、散热、寿命和标定一起变难 |
| 计算平台 | 躯干内运行类似车端 FSD 计算机 | AI5 被公开口径描述为面向后续更大模型和端侧推理 | 长期依赖云端会受限,端侧能效比会很早限制产品形态 |
| 成本目标 | AI Day 2022 给过低于 2 万美元的长期设想 | 财报电话会继续把 2 万美元级别作为规模化目标 | 这取决于执行器、磁体、线束和装配良率,模型只是其中一项 |
| 部署阶段 | 先在 Tesla 工厂内部测试 | 多次财报口径提到内部使用、设计迭代和后续产线目标 | 工厂更像训练场和验证场,外部销售时间表仍要谨慎看 |手部升级看着是小改动,放在机器人里其实很大。工厂里的「拧螺丝、插连接器、搬零件、贴标签」和家庭里的「拿杯子、开门、叠衣服」,只靠手臂大范围运动很难做好。手指要有足够多的接触点,也要知道物体是否滑动、是否易碎、接触面在哪里,这些都得一起考虑上。

一根没有销钉的手指
2026 年 4 月 16 日,第三方拆解提到一组 WIPO 公开的 Tesla 手和前臂专利。专利本身不等于量产设计,但其中 WO 2026/080693 很能看出结构取舍,Joint Assembly for Robotic Appendage,也就是机器人附肢关节组件。当时在推特看到这个报告,我印象很深。
拆解材料里的思路是绕开传统销钉铰链,用一块扁平复合件夹在两节指节之间,上下两层弹性体,中间夹一片很薄的增强片,材料候选里出现了 Vectran 和 Nitinol,前者是液晶聚合物纤维,后者是镍钛超弹性合金,用来做方向性刚度。

这个设计要控制的是弯曲方向,手指弯曲方向要软,拉伸、压缩、剪切、扭转、侧摆这些方向要硬,传统销钉靠几何结构限制多余自由度,这个方案靠各向异性刚度来限制。工程上它有三个潜在收益,指节之间能形成接近滚动接触、转动轴随角度移动,更像真实手指;弹性体自带回弹,不一定要额外回位弹簧;腱绳还能穿过中性面,减小反复弯曲带来的疲劳。
这个案例看着像结构设计,背后其实牵连了灵巧手里一连串问题,一个关节结构会影响手指回弹、腱绳走线、腕部布局、前臂空间、装配公差和维修方式,它能不能在一天几千次抓取后还保持一致,演示里看不出来,需要实际到真实工作场景长期使用才知道有没有问题。
Optimus 的 AI 是怎么做的
Optimus 和 FSD 同源是 Tesla 反复强调的技术点,AI Day 2022 提到,机器人躯干里的计算机来自车端 FSD 计算机,软件栈也复用了车辆里的目标识别、occupancy network、室内导航和运动规划,也有第三方把 Optimus 描述成 8 个摄像头输入,输出到 78 个执行器的端到端系统。
Tesla 其实不是「单一端到端神经网络」,FSD 完整构建涉及 48 个网络,更准确的说法是,Tesla 是追求端到端可学习的统一系统,工程实现更可能是共享表示的多任务 multi-head 架构。
| 层 | 公开资料里常出现的能力 | 对机器人有什么用 |
|----|------------------------|------------------|
| 视觉输入 | 8 个自动驾驶级摄像头,纯视觉路线 | 降低传感器成本,代价是深度和冗余要靠数据与模型补 |
| 3D 表示 | Occupancy Network、深度估计、3D 重建 | 把 2D 画面转成可通行区域、障碍物和物体位置 |
| 任务理解 | Grok 或语言层处理指令 | 把用户语言或工厂任务转成可执行步骤 |
| 运动与操作 | 运动规划、操作规划、平衡控制 | 把目标位姿变成身体和手的连续动作 |
| 执行输出 | 第三方整理提到 28 个身体执行器 + 50 个手部执行器 | 高维动作空间,调试和安全比自动驾驶更难 |自动驾驶的动作空间其实不大,方向盘、油门、刹车这几样基本就说完了,但人形机器人是另一回事,Optimus 按 78 个执行器算,每一个时间步都得把身体、手臂、手指、平衡、接触一起兼顾到,杯子稍微滑一下,手指力、手腕、手臂轨迹、重心也需要同时跟着调整。
端到端路线能省掉模块之间一堆手写接口,让视觉、语言、空间和动作通过统一训练互相影响,但出了错很难定位,抓错零件时,是深度估计错了,物体语义错了,动作头错了,还是执行器跟踪失败?工程系统仍然需要日志、状态回放、安全控制器和可解释的中间信号。
把 Optimus 放到工程系统里,我会先拆成四个接口,这样更容易看清楚它难在哪。
| 接口 | 输入 | 输出 | 怎么验收 |
|------|------|------|--------------|
| 视觉到 3D | 多摄像头图像、本体姿态 | occupancy、物体位置、可达空间 | 遮挡、反光、窄通道、低纹理物体下是否稳定 |
| 语言到任务 | 人类指令、工厂 SOP、当前场景 | 子任务序列和失败恢复策略 | 指令变化后是否仍然走合理流程,失败能否重新规划 |
| 任务到动作 | 子任务、末端目标、接触状态 | 身体、手臂、手指动作轨迹 | 频率、延迟、抖动、接触力是否在安全范围 |
| 动作到执行 | 关节目标、电流限制、传感器反馈 | 执行结果、故障码、急停状态 | 长时间重复操作后是否漂移,故障是否可定位 |这四个接口放到小机器狗上也能对上,只是尺度差很多。我的狗只有「语言到固定动作」和「动作到 PWM」,少了视觉到 3D 和接触状态。Optimus 的难点是四个接口都要同时成立,而且任何一层出错都可能被统一模型吞进黑盒里。
数据从哪来,量产难在哪
Tesla 的优势常被概括成车队数据,这里只说对一部分,车队数据能给 Optimus 带来视觉常识、空间理解、光照适应、动态物体预测和 occupancy 表示,但汽车并不处理杯子摩擦系数,也不用手指判断纸箱是否瘪了,其实现在机器人最缺的是真实物理世界的接触数据。按目前公开资料,Tesla 的 Optimus 数据主要来自这四类:
| 数据源 | 它补什么 | 还缺什么 |
|--------|----------|--------------|
| 车辆 fleet | 视觉常识、空间理解、occupancy 表示 | 抓取、力控、触觉、接触失败 |
| 人类第一视角演示 | 任务语义、手部细节、工具使用 | 机器人本体状态和真实执行误差 |
| Digital Dreams / 神经网络世界模拟器 | 长尾场景、光照、物体位置、初始状态变体 | 生成数据的物理一致性仍要真机验证 |
| 工厂 Optimus 在线反馈 | 最接近部署分布的成功和失败样本 | 受机器人数量、任务边界和安全限制影响 |所以才有了人类操作员带着头盔和背包相机去现场采集这种做法。前段时间我还看到国内的具身智能公司和家政公司合作,让阿姨带着传感器和摄像头去打扫卫生,这类合作也是在补物理世界接触数据。

机器人数据比自动驾驶慢得多,车队能靠满街的车每天一起采,遥操作通常一人一次只教一台,真机自主采更慢,失败还会磨损硬件、打断产线、带来安全风险,所以这事才这么难,但我还是挺看好这个方向。
机器人公司之间的差距,会慢慢体现在样本、训练和硬件改动的速度上,谁能更便宜、更稳定地采到失败样本,再把它们带进下一轮训练和硬件改动,谁的能力迭代就拉得更开。

数据是一道坎,量产是另一道。
Tesla 每次财报电话会都会聊不少 Optimus,作为投资人,我一般会把他们讲的和当前真做到的分开辩证看,把 2024 到 2026 年的连续口径连起来,能看出一些持续的变化,也能看出每次难点在哪里。
| 公开口径 | 卡在哪里 |
|----------|----------|
| 先在 Tesla 工厂内部使用 | 工厂是任务场,也是数据场和安全边界 |
| 机器人尚未 design-locked | 硬件定型还在推进,模型迭代速度代表不了整机迭代速度 |
| 目标产线从 1,000 台/月到更高规模 | 难点在执行器、电池、线束、装配和质检良率 |
| 目标在规模化后把成本压到 2 万美元以下 | 这依赖全新供应链,软件降本只占一部分 |
| 稀土永磁体供应被点名影响 Optimus | 执行器会被材料和供应链约束 |比交付年份更难绕开的,是上面这些约束。人形机器人很难等模型训好再开产线,硬件、数据、制造通常一起推进。手部一改设计,前臂结构、线束、触觉传感器、控制器和供应链都要跟着动,执行器良率不稳,产能目标就会被最慢的零件给拖住。

比交付年份更难绕开的,是上面这些约束,人形机器人很难等模型训好再开产线,硬件、数据、制造通常一起推进,手部一改设计,前臂结构、线束、触觉传感器、控制器和供应链都要跟着动,执行器良率不稳,产能目标就会被最慢的零件给拖住。
从公开资料看,Tesla 赌的是三件事的组合,真实场景数据、制造规模和垂直整合。FSD 给它视觉和训练基础设施,工厂给它受控任务和反馈,制造体系给它降本路径,但手部可靠性、执行器成本、安全保护和真实工位 ROI 只要有一项卡住,这些优势也很难落到产品上。
后续 Optimus 的验证点会集中在几样东西上,手部结构的长期可靠性,失败样本回到训练和真机验证的速度,模型的可排错接口,产线目标背后的执行器和供应链支撑,公开资料里的 Tesla 路线如果成立,靠的是车队视觉经验、工厂任务、世界模拟器、训练集群和制造体系一起跑通。
几家公司的不同路线
现在做人形机器人的公司不少,路线和押的方向差别其实挺大。
| 玩家 | 路线 | 押的方向 | 观察点 |
|------|------|------------|------------------|
| Tesla Optimus | 纯视觉、FSD 迁移、工厂试跑、自研执行器 | 失败样本和制造规模 | 手部、执行器成本、真实工位 ROI |
| Figure | Helix / Helix 02,全身 VLA 和工厂任务 | on-device VLA 和长程 loco-manipulation(边走边操作) | 演示外的稳定性、维护成本 |
| Google DeepMind | Gemini Robotics,高层 ER + 低层 VLA | 通用多步推理接机器人动作 | 伙伴硬件上的泛化和安全边界 |
| NVIDIA | Jetson Thor、Cosmos、Isaac、GR00T | 卖芯片、仿真、世界模型和基础模型工具链 | 生态是否能跨机器人稳定复用 |
| Boston Dynamics | 传统控制积累 + AI 增强 | 可靠运动控制和工业部署 | 成本、通用操作能力 |
| Unitree 宇树 | 高性价比硬件、运动能力、开发者市场 | 用低价格扩大硬件基数 | 软件生态和安全任务能力 |
| AGIBOT 智元 | 多形态产品、数据集、全栈平台 | 国内供应链和真实任务数据 | 公开可验证的任务覆盖和持续运行 |这七家其实分两拨。一拨自己造整机,Tesla、Figure、宇树、智元都是从硬件到模型自己全包。另一拨不绑某一台机器人,Google DeepMind 做的是能接到不同本体上的智能层,NVIDIA 干脆把算力、仿真、世界模型和基础模型做成工具链卖给所有人。前一拨赌的是数据和制造能不能咬合,后一拨赌的是自己那层能不能跨机器人复用。

平台这条路听着省事,风险还是接口边界。上层指令太抽象下层接不住,下层失败说不清上层也没法重规划,跟前面 VLA 那章讲的问题很像。
其实也不是只有 VLA 一条路。Boston Dynamics 没有去蹭大模型叙事,靠电动 Atlas 和扎实的运动控制照样进工厂物流。工业现场看的是节拍、故障率和安全认证,而非演示效果好不好看。国内这边信号最实在的是价格和供应链速度,宇树 G1 官方起价 1.35 万美元,硬件基数能很快铺开,能不能做通用任务、能不能长期稳定还得持续来看。我那台小机器狗就停在最基础的固定动作层,这些路线对它来说都还太远。

这些路线背后是三种取舍。工厂场景普遍被当成第一站,因为环境可控、ROI 算得清、任务边界能限定。家庭场景最难,环境乱、用户容错低,还得做到安静、安全、隐私可控。平台公司则选择先卖工具链,因为大多数机器人公司本身就缺数据、仿真、边缘算力和训练框架。
从软件往具身智能走
如果你也是偏软件的工程师,想继续往下看具身智能,下面这些系统层知识绕不开。
- 嵌入式和实时系统:GPIO、PWM、I2C、UART、SPI、定时器、中断、RTOS
- 机器人运动学:坐标系、正逆运动学、Jacobian、末端位姿
- 控制基础:PID、MPC、状态估计、采样频率、延迟和稳定性
- 感知和 SLAM:相机模型、深度、IMU、LiDAR、外参、时间同步
- 模仿学习和强化学习:行为克隆、ACT、Diffusion Policy、reward、Sim2Real
- 数据工程:遥操作、episode 格式、视频和状态同步、标注、评估
放到一张图里,它是从芯片、执行器、传感器一路往上到算法和系统的一整个栈。单独看模型,很多问题根本看不出来;对着完整技术栈图看,每一块大概在哪一层会清楚很多。

资料串起来大概是这个顺序。先从小机器狗这类硬件项目入手,因为它们刚好能把「端云协同 + 本地动作」连起来。唤醒、联网、模型调用、能力描述、串口协议、动作执行、状态回传都能在一个小系统里遇到。项目不大,但每个环节都可能真实失败,一个个解决的过程,反而最有探索感。
端云协同和 MCP 跑过一遍后,再看 ACT / ALOHA,会更容易理解低成本遥操作和 action chunking;接着看 Diffusion Policy,动作为什么要建模成分布会更清楚;再到 RT-1、RT-2、Open X-Embodiment、OpenVLA 这条线,VLA 和跨具身数据就能接上;最后看 π0、π0.5、SmolVLA、Gemini Robotics、Helix、GR00T N1.5,产业界怎么把高层推理、低层动作和边缘部署拼到一起,也会落到更具体的问题上。
要我说具身智能的重点,就「感知、空间、动作、力矩」这四个词,大致也是难度从轻到重。感知 AI 已经够强,空间还在补课,动作刚学会一点,到力矩这一层,就要面对电机、结构、接触和供电这些实打实难做的东西。AI 越靠近物理世界,能靠模型解决的部分越少,剩下的更多是硬件的事。
参考文献
模型与算法
- RT-1: Robotics Transformer for Real-World Control at Scale,Google Robotics, 2022。
- RT-2: New model translates vision and language into action,Google DeepMind, 2023。
- Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,Columbia + MIT CSAIL, 2023。
- Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,ACT / ALOHA, 2023。
- Open X-Embodiment,Google DeepMind + 33 institutions, 2023。
- OpenVLA: An Open-Source Vision-Language-Action Model,Stanford + Physical Intelligence + Google DeepMind, 2024。
- π0: A Vision-Language-Action Flow Model for General Robot Control,Physical Intelligence, 2024。
- π0.5: a VLA with Open-World Generalization,Physical Intelligence, 2025。
- SmolVLA: Efficient Vision-Language-Action Model trained on LeRobot Community Data,Hugging Face, 2025。
- Gemini Robotics,Google DeepMind。
- Gemini Robotics On-Device brings AI to local robotic devices,Google DeepMind, 2025。
产业、硬件与工具链
- Helix: A Vision-Language-Action Model for Generalist Humanoid Control,Figure AI, 2025。
- Introducing Helix 02: Full-Body Autonomy,Figure AI。
- NVIDIA Jetson Thor,NVIDIA。
- Cosmos World Foundation Model Platform for Physical AI,NVIDIA Research, 2025。
- GR00T N1.5,NVIDIA GEAR。
- LeRobot,Hugging Face。
- SO-ARM100,SO-100 / SO-101 低成本机械臂硬件。
- xiaozhi-esp32,开源 ESP32 AI 语音助手。
- Genesis,开源物理仿真平台。
- NVIDIA Isaac Lab,机器人学习框架。
- Tesla AI Day 2022 transcript,Optimus 早期技术披露。
- AI Training for Tesla Optimus Explained,Optimus AI 训练、数据来源和世界模拟器第三方整理。
- Tesla Earnings Call Transcripts,2024 Q2 到 2025 Q3 财报电话会 Optimus 口径的公开 transcript 聚合入口。
- The Pinless Finger: What Tesla Put Where the Hinge Should Be,Optimus Gen 3 手和前臂 WIPO 专利第三方拆解。
- Unitree G1,宇树科技官方商城。
更多阅读
想接着看 AI 工程这一类,我之前几篇 X 长文可以按这个顺序读:
- 你不知道的 Claude Code,架构、治理与工程实践
- 你不知道的 Agent,原理、架构与工程实践
- 你不知道的大模型训练,原理、路径与新实践
- 你不知道的 AI Coding,非技术人的上手、场景与实战
- 你不知道的 GEO,AI 可见性的原理、实践与取舍
初稿完成于 2026 年 5 月,6 月也在持续修订中,断断续续写了2个月,具身智能领域变化很快,部分数字和产品进展可能继续变化,发现错误欢迎指出。
参考与延伸
参考来源
原始来源:https://x.com/hitw93/status/2063447352346812576?s=46
作者:Tw93 (@HiTw93)
内容结构
1 个主章节,13 个子章节,17 张图片,12 个代码块。
阅读提示
建议先看导读层和目录,再按感兴趣的模块挑重点深入。